一 广播播出音频处理器实现研究
广播播出音频处理是广播系统实现高质量节目播出的关键技术环节,其核心目标在于对音频信号进行精细化处理,确保其在响度一致性、频谱平衡性、动态范围控制及失真抑制等方面满足广播播出标准与听觉感知要求。随着我国广播设备自主化进程的推进,构建具备自主知识产权的音频处理技术体系尤为重要。本章基于国产化音频处理器的研发实践,系统阐述广播播出音频处理的关键方法、技术路径与系统实现,特别在基于听觉模型的智能处理方面进行了深入探索。
1.音频处理的总体架构与功能组成
广播播出音频处理器采用模块化、串行处理的系统架构,依次由五频段均衡器、两频段自动增益控制(AGC)控制器、五频段动态范围控制(DRC)控制器、削波器(Clipper)以及带宽控制滤波器五大核心模块构成,如图1所示。该设计充分考虑了广播节目的多样性与播出链路的稳定性要求,实现了从信号修饰、电平稳定、动态压缩到幅度限制的全流程精细化控制。特别值得一提的是,系统在多处关键处理环节引入了听觉感知模型,使处理过程更加贴合人耳听觉特性。
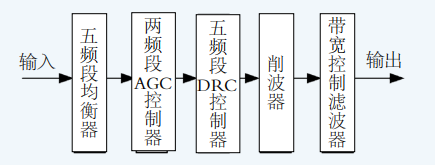 图1 音频处理器总体实现框图
图1 音频处理器总体实现框图
2.五频段均衡器的设计与实现
五频段均衡器作为信号处理的首个环节,负责对音频频谱进行有针对性的修饰与校正。其结构由一个低频搁架式均衡器、三个峰幅度均衡器及一个高频搁架式均衡器串联组成,如图2所示。低频与高频搁架式均衡器分别负责对最低频段和最高频段进行整体性提升或衰减;峰幅度均衡器则用于对特定中心频率附近的信号进行精细调节。
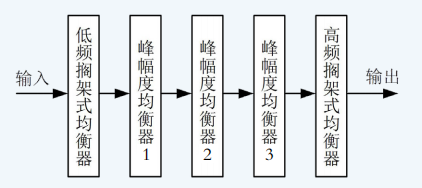 图2 五频段均衡器实现框图
图2 五频段均衡器实现框图
在技术实现上,均衡器设计遵循从模拟原型到数字滤波器的映射路径。首先在模拟域设计一阶或二阶搁架式滤波器及峰幅度滤波器原型,随后采用双线性变换法将其转换为数字滤波器。双线性变换虽会引入频率畸变,但通过预畸变校正可有效保证数字滤波器与模拟原型在关键频点特性上的一致性。数字均衡器具备参数独立可调、稳定性高的特点,适用于实时音频处理系统。
3.两频段AGC控制器的增益稳定策略
自动增益控制(AGC)是保障播出节目响度一致性的关键。本系统采用两频段式AGC结构,通过Linkwitz-Riley四分频网络将信号分割为低频与高频两个子带,并分别进行功率估计与增益计算,如图3 所示。该设计能有效克服强低频信号对全频段增益计算的干扰,避免因低频能量过大而导致中高频语音响度被不当压低,从而提升节目整体的响度感知均匀性。
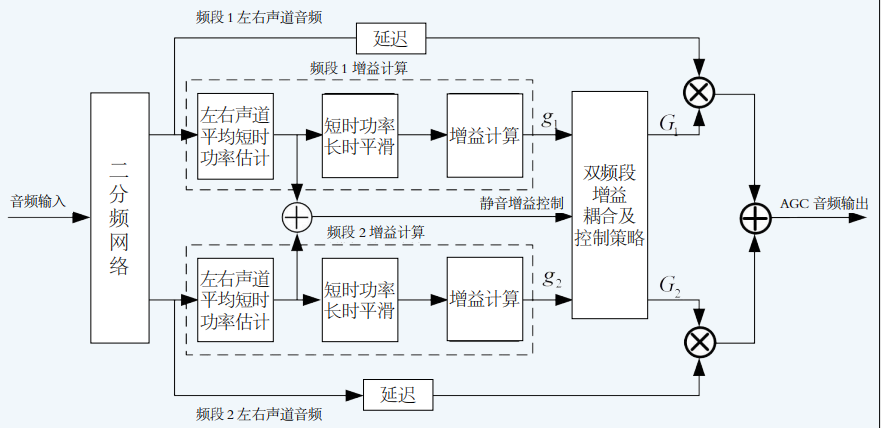 图3 双频段AGC控制器实现框图
图3 双频段AGC控制器实现框图
在功率估计方面,系统采用基于一阶IIR滤波器的自回归模型进行短时平均功率计算,该方法仅需单一存储单元,计算效率高,特别适用于高采样率环境。长时平滑模块则通过建立时间(Attack Time)与恢复时间(Release Time)独立可控的一阶IIR滤波器实现,其参数根据模拟电路响应特性进行数字化映射,确保动态响应行为符合广播操作习惯。双频段增益协同机制约束低频段增益不高于高频段,且差值不超过6dB,有效维持了节目频谱包络的自然性。
4.五频段DRC控制器的动态范围管理
动态范围控制(DRC)用于调控音频信号的动态范围[1],既可压缩大信号以防超标,亦可扩展小信号以提升整体响度。本系统采用五频段DRC结构,参考二分频网络工作原理[2],通过对全频带信号进行子带划分,实现对特定频段(如具有强烈冲击的低频乐器)的独立动态控制,而不影响其他频段信号的正常表现。如图4所示。
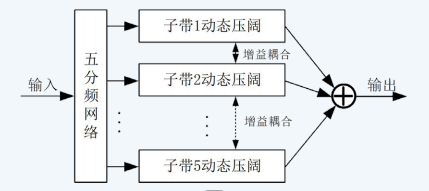 图4 五频段DRC实现总体框图
图4 五频段DRC实现总体框图
每个子带DRC模块包含峰值检测、压扩曲线映射、增益计算与增益平滑四个单元,如图5所示。峰值检测采用可变状态的IIR滤波器,根据信号变化趋势动态切换建立与恢复状态。压扩曲线设计为包含噪声门、扩张区、线性区、压缩区及限幅区的多段式软过渡曲线,通过二次函数连接各段,显著改善状态切换处的听觉连续性。增益平滑模块同样采用建立/恢复时间独立配置的IIR滤波器,确保增益变化的自然平滑。为避免多频段独立控制导致频谱包络失真,系统引入以中频段为参考的增益耦合策略,约束相邻频段间的增益差,保障整体音色的协调性。
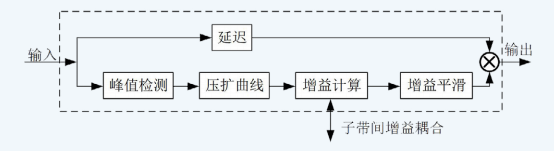 图5 子带动态压阔(DRC)实现框图
图5 子带动态压阔(DRC)实现框图
5.基于听觉模型的智能削波与带宽控制
削波器作为播出链路的最终幅度保障,承担抑制信号过载、防止硬件损伤的关键任务。传统硬削波因导数不连续会产生大量高次谐波,导致严重听觉失真。本系统在基础软削波方案基础上,重点研发了基于听觉掩蔽模型的智能削波算法,实现感知无损的限幅处理。
该智能削波算法的核心在于充分利用人耳的听觉掩蔽效应。系统首先通过心理声学模型分析输入信号的频谱特性,计算各临界频带内的掩蔽门限。在一个临界带内,强信号(掩蔽音)会对其邻近频率的弱信号产生掩蔽作用;当弱信号低于该掩蔽门限时,人耳将无法感知其存在。系统建立的听觉模型能够精确模拟这一现象,生成随信号内容自适应的频域掩蔽曲线。图6为听觉模型中所采用的掩蔽曲线。
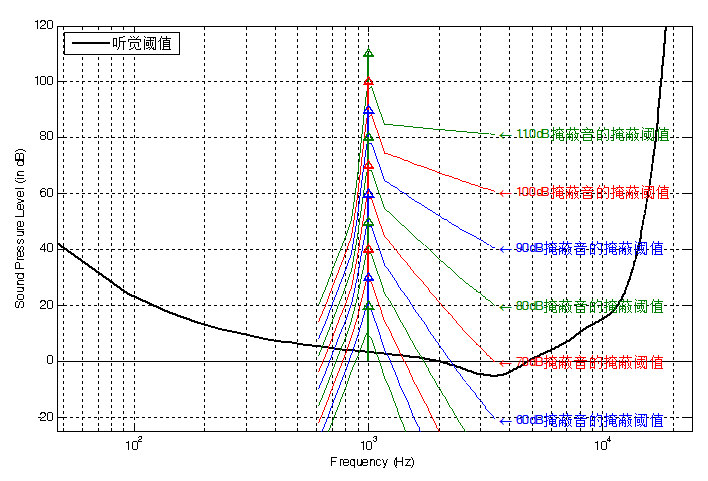 图6 听觉模型的频域掩蔽曲线
图6 听觉模型的频域掩蔽曲线
在算法实现上,系统采用分帧处理方式,将削波问题转化为带约束的优化问题:在满足时域幅度限制的前提下,最小化处理前后信号频谱的加权差异,其中权重为根据听觉模型计算出的掩蔽门限倒数。通过迭代优化,使引入的削波失真能量主要分布于掩蔽门限较高的频段,从而确保失真成分被人耳自然掩蔽。这种基于听觉模型的削波器能够有效避免传统削波方法引起的谐波干扰与拍频现象,显著提升高动态范围节目的听觉质量。
为应对超高电平情况下的谐波混叠问题,系统结合超采样技术:在进行智能削波前提升采样率,削波后经低通滤波再降采样至目标采样率,进一步将不可避免的高次谐波推至可听频带之外。如图7和图8所示。最终,处理器输出信号经六阶Butterworth低通滤波器进行带宽限制,截止频率设为15kHz,确保输出信号严格符合广播传输频谱规范,实现技术指标与听觉体验的双重优化。
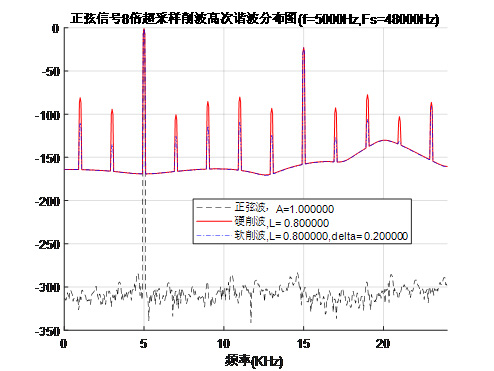 图7 正弦信号8倍超采样削波后频谱混叠干扰细节示意图
图7 正弦信号8倍超采样削波后频谱混叠干扰细节示意图
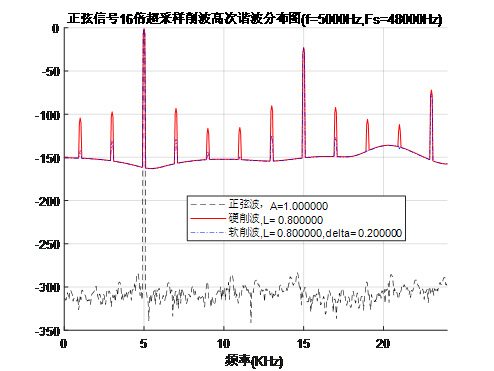 图8 正弦信号16倍混叠干扰细节示意图
图8 正弦信号16倍混叠干扰细节示意图
6.小结
本章系统阐述了广播播出音频处理的关键技术路径与实现方法,涵盖均衡处理、动态控制、增益调节与失真抑制等多个方面。所实现的各音频处理各算法模块,为我国广播音频处理设备的自主化与高性能化提供了可行的算法支撑。
二 硬件系统应用方案
广播播出音频处理器的硬件系统是实现国产化替代、保障功能落地与高可靠播出的核心载体。本系统采用“核心处理+接口扩展+网络冗余+人机交互”的模块化架构,核心器件选用国产芯片,既满足广播音频低延迟、高可靠的需求,也实现自主可控的替代目标。系统硬件由ARM算力核心板、国产FPGA处理单元、系统主控CPU、国产交换机芯片、音频接口电路、人机交互单元及扩展板组成,如图9所示。各模块通过I2S、RGMII、MIPI等接口协同工作,覆盖音频处理、网络通信、节目类型智能识别等设计需求。
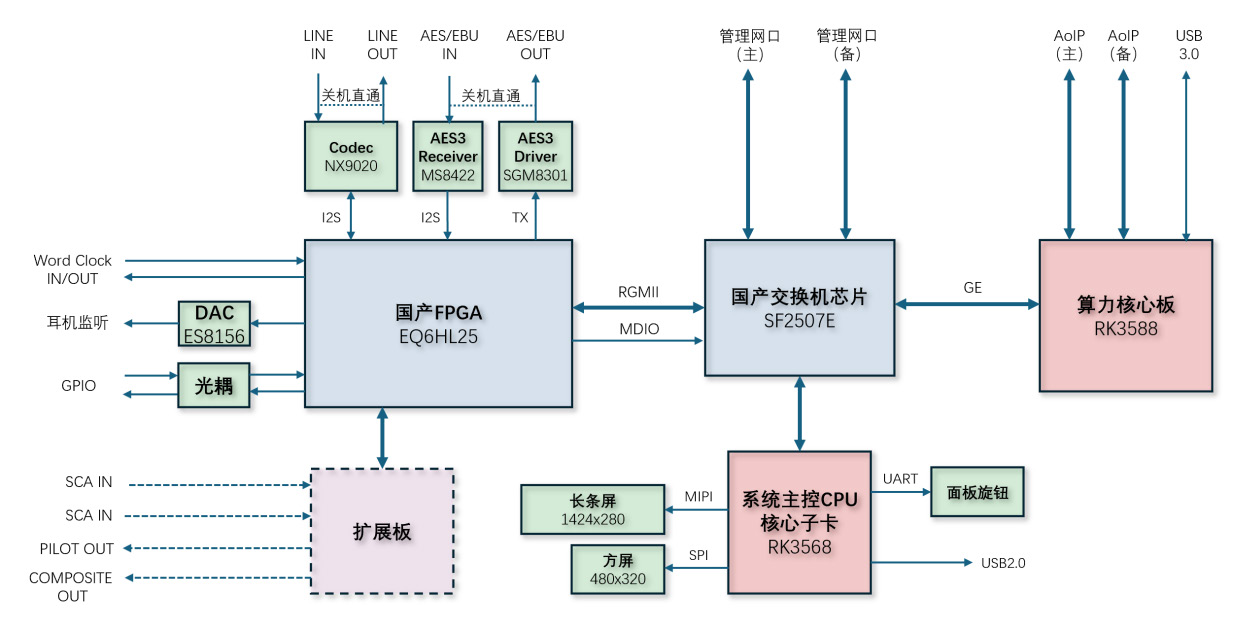 图9 广播音频处理器硬件系统架构
图9 广播音频处理器硬件系统架构
1.核心处理模块
核心处理模块是音频算法与智能功能的执行载体。本方案基于多核ARM处理器RK3588提供算力支撑,实现两类复杂任务:一是AI节目分类与自适应调整,通过AI模型实时分析音频特征,自动区分语言/音乐类节目并匹配最优处理参数;二是实现立体声增强、高频增强、两频段AGC(自动增益控制)、五频段动态压缩、左右声道相位偏移校正、ITU BS-412功率限幅器等算法。同时,该核心板通过GE接口与交换机芯片交互,承担AoIP信号的协议处理与数据转发,保障网络音频的标准兼容性。
在接口板卡中,选用了一块国产FPGA芯片(EQ6HL25)作为系统国产化的核心器件之一,该芯片凭借并行计算特性,承担低延迟实时音频处理任务,通过I2S接口对接各类音频输入/输出接口模块,保障广播音频的高实时性需求。
2.基带音频接口模块
基带音频接口模块包含模拟与数字信号链路,并设计断电直通机制保障播出安全性。
在模拟基带音频接口部分,采用国产Codec芯片NX9020实现LINE IN/OUT模拟信号的编解码,将模拟信号转换为I2S格式送入FPGA,同时将处理后的I2S信号转换为模拟信号输出;此外,通过 DAC 芯片 ES8156 扩展耳机监听接口,支持运维人员实时监听音频状态。
在数字基带音频接口部分,采用MS8422与SGM8301 芯片实现AES3信号的收发:MS8422将输入的数字信号转换为I2S格式送入FPGA,SGM8301将FPGA处理后的信号转换为AES3格式输出。
系统还设计了“关机直通”电路,设备断电时直接导通模拟和数字基带信号链路,避免播出中断。
3.网络通信模块
国产交换机芯片SF2507E作为网络数据转发核心,通过RGMII/MDIO接口与FPGA、系统主控CPU交互,同时提供管理网口(主备)与AoIP接口(主备)的物理链路支撑,是网络通信的硬件中枢。
在网络接口设计方面,系统采用主备冗余的AoIP音频接口,严格遵循AES67、ST 2110-30 标准,主备接口符合ST 2022-7 冗余协议,保障网络音频信号的稳定传输,满足广播系统高可用性要求。同时,管理网口也采用主备冗余架构,提升系统配置与监控的网络可靠性。
4.人机交互与系统控制模块
系统采用基于ARM架构的RK3586模块作为系统主控CPU核心子卡,承担人机交互与系统管理功能。
在显示单元方面,通过MIPI接口连接前面板长条显示屏,用于显示音频处理环节的各类表头界面;通过SPI接口连接前面板右侧方屏,用于基本信息显示与设备菜单配置,实现操作可视化与音频状态实时监控。
在操作交互方面,通过UART接口连接面板摇杆控制器,配合快捷菜单设计,支持初次配置时的快速参数设定,降低运维复杂度。图10为广播音频处理器前面板显示与交互部分的设计渲染图。
 图10 前面板显示与交互部分设计渲染图
图10 前面板显示与交互部分设计渲染图
在系统管理方面,RK3586模块协调FPGA、算力核心板、交换机芯片的工作状态,实现参数下发、状态采集、故障告警等功能,是系统的控制中枢。
5.硬件设计的国产化与适配性
本系统核心器件(ARM核心板RK3588/RK3586、FPGA EQ6HL25、交换机芯片SF2507E等)均选用国产芯片,实现了硬件层面的自主可控,完成核心器件的国产化替代。同时,模块化架构与算力资源的精准分配,既保障各类实时音频处理算法的低延迟运行,也支撑AI节目类型识别、AoIP 标准兼容等复杂需求,实现音频处理核心功能与国产化目标的双重落地。
三 音频处理实际效果分析
1.根据广播节目常见类型,准备三种测试素材
如表1所示。
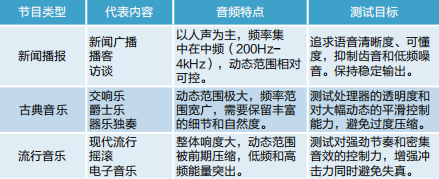 表1 测试素材分类与测试目标
表1 测试素材分类与测试目标
2. 音频处理器参数测试
(1)设置测试基准将均衡器、AGC、动态压缩器全部关闭或设置为直通(Bypass) 模式。
(2)均衡器(EQ)模块设置如表2所示。
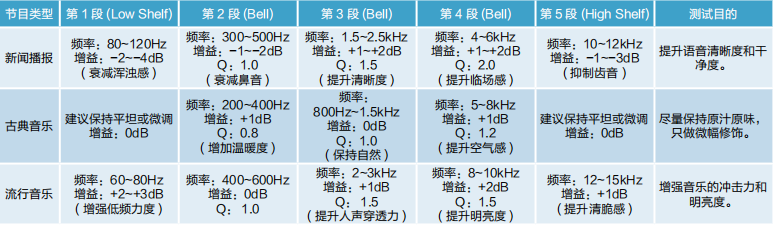 表2 不同节目类型的均衡器参数设置
表2 不同节目类型的均衡器参数设置
AGC类型:全频段 AGC。
触发时间:1.2秒(1200ms)。
恢复时间:6.4秒(6400ms)。
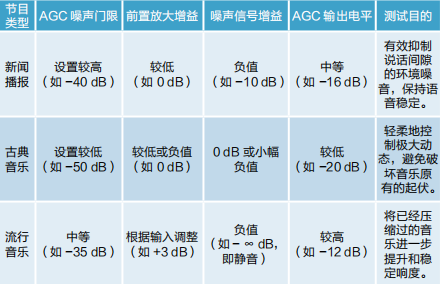 表3 AGC参数按节目类型调整
表3 AGC参数按节目类型调整
触发时间:10ms。
恢复时间:500ms。
◆新闻播报:重点设置中高频段(频带3、4)的压缩门限,不可过度压缩,确保语音电平稳定;对低频(频带 1、2)设置较高的噪声门限与扩张门限,以削减隆隆声;
◆古典音乐:压缩比设置应非常柔和,压缩门限设置较高(即仅对极大峰值起作用)。增益补偿尽量小,避免提升本底噪声;
◆流行音乐:可以进行较大比率的压缩,尤其在低频(频带1)与高频(频带5),以控制能量并提升持续响度。适当使用增益补偿。
3.不同场景下音频处理实际效果主观评测分析
(1)“新闻播报”模式评测效果该模式在处理纯人声节目时表现出色。与原始信号相比,处理后的语音清晰度显著提升,人声更加突出、扎实,背景中的低频嗡嗡声和交流声得到有效抑制。该模式能极大优化语音类节目的可懂度与稳定性,特别适合新闻、播客、谈话类节目的播出,实现“听得清、听得舒适”的核心目标。
(2)“古典音乐”模式评测效果对于大动态的古典音乐,算法未对音乐进行“暴力”的压缩与限幅,而是巧妙地跟随音乐本身的动态起伏。在强奏乐段,处理器有效防止过载失真;在弱奏乐段,丰富的细节和空间感得以完整保留。基于听觉模型的动态控制策略更为细腻和自然。该模式成功地在控制峰值和保留音乐艺术性之间取得平衡,适用于对保真度要求高的音乐广播、音乐会直播等场景。
(3)“流行音乐”模式评测效果该模式旨在进一步提升节目的冲击力与响度,以适应移动收听、车载收听等非理想环境。该模式有效提升音乐的整体响度与紧凑感:低频的适度增强让节奏更有力,高频的提升增加音乐的“亮度”与“穿透力”;动态压缩器对各频段,尤其是低频和超高频能量的控制非常有效,避免因过度提升导致的失真。 该模式契合现代流行音乐的播出需求,通过积极的频响优化和多段动态控制,显著增强音乐的感染力及对不同播放环境的适应能力。
四 展望
结合当前广播融媒体业务的发展趋势,未来音频处理可在两个方向拓展:一是应用AI模型结合声学特征提取算法,实现音频节目的自动识别和参数自动调整,使音频处理能根据节目类型自适应提升音频;二是将算法模块移植至软件端,利用服务器结合AoIP虚拟网卡,实现多路流媒体节目的批量处理。通过“音频处理核心算法+AI+云端部署”,可低成本实现海量流媒体节目的音质提升。
本文系2024年中央广播电视总台超高清视音频制播呈现国家重点实验室研究项目“广播播出音频处理器国产替代研究”(项目编号:CMGSKL2023KF011)的研究成果之一,由该研究项目资助。
参考文献:
[1].G.W.McNALLY,"DynamicRangeControlofDigital AudioSignals",J.AudioEng.Soc.,Vol.32,No.5,1984 May,pp316-327.
[2].STEFANIACECCHI,VALERIABRUSCHI,STEFANO NOBILI,ALESSANDROTERENZI,VESAVALIMAKI,"CrossoverNetworks:AReview",J.AudioEng.Soc.,Vol.71,No.9,2023September,pp.526-551.
![]()